

第6回 大規模言語モデルと対話型生成AI
前回までのコラムにおいては、深層学習技術の発展を受けたAIシステムに対する品質やトラストの動向についてまとめてきました。2017年前後から産官学において非常に活発な議論が行われ、ある程度何が求められるのかということは明確になりました。2022年度半ばまで、このような議論の対象となるAIといえば主に、訓練データを基にして特定のタスクを扱えるようにしたものでした。つまり、不良有無の分類、画像に写っている物体の検出、売上げの予測など、「入力から出力の求め方」をデータから学ぶ教師あり学習技術が産業応用では多く用いられてきました。
一方で、2022年半ばにChatGPTが公開されてからは、AIの種別として、このように「何でもできる(かのように見える)」対話型生成AIが話題の中心となりました。今回のコラム以降は、このような対話型生成AIおよび、その基盤技術となる大規模言語モデルの品質・トラストについて論じていきます。
大規模言語モデル
ChatGPTというAIあるいはその提供サービスの名前とは別に、GPTあるいはバージョン名付きでGPT-3.5やGPT-4といった名前も聞いたことがあるかもしれません。技術的には、対話型生成AIサービスであるChatGPTの基盤となっている機械学習モデルがGPT-3.5やGPT-4と呼ばれるもので、機械学習モデルの種別としては大規模言語モデル(以後LLM: Large Language Model)と呼ばれます。OpenAI以外でも、Googleが提供しているGeminiというAIサービスでは、モデルとしてはGemini 1.5 Proといった選択肢があります。Meta社は、Llamaというオープンソースのモデルシリーズ(Llama 3.2-11Bなど)を提供しています。(名称やバージョンは本コラム執筆時のものです)
ChatGPT以前から言語モデルという技術は存在し、活用されています。言語モデルは端的には、図1のように、単語の出現確率を学習したものです。従来においても、この言語モデルを共通のモデル(基盤モデルと呼びます)として利用し、さらに追加訓練(ファインチューニング)することで、文章の要約や感情分析などの専用モデルを構築することは盛んでした。
図1 実現の「とても雑な」イメージ
■言語モデルが学習し、出力できること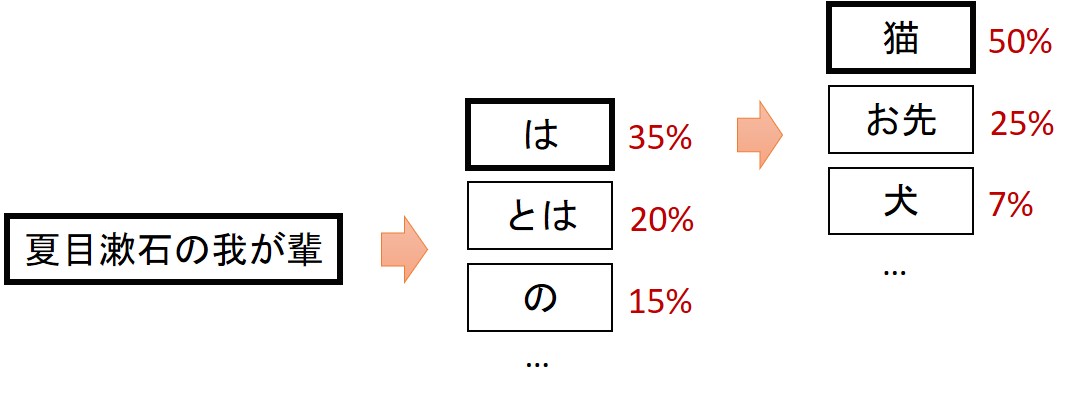
■これを大規模学習により極めていくと…
■実際には、「返答が人間にとって望ましいかの判断基準」を別途学習するなどの工夫が加えられて実用的なものとなっている
LLMは、その名の通りこの言語モデルの学習を大規模にしたものです。非常に端的には、この「続きを予想する」ということで、非常に高度な応答・会話ができるようになったというイメージです。当然、人にとって望ましい応答をするような工夫も必要になりますし、プロダクト・サービスとしては不正な入力あるいは不適切な出力のフィルタリングといった機構も必要になるでしょう。いずれにしても図1にあるように、「辞書や知識・ルールを調べて答えている」わけではない、という機械学習技術としての性質は、当然把握することが必要です。
なお、「大規模」の程度について詳細情報は非公開のモデルも多いですが、GPT-3.5などの古いバージョンの時点でも、1000億個以上のパラメーターを持つニューラルネットワークモデルに対し、(かなり前処理で絞った上で)500GB以上の訓練データを用いていたとされています。それを可能にする専用のGPU (Graphics Processing Unit) も1個数百万円することも多く、それらを100個や250個などは少なくとも揃えてといった形になります。電力使用量なども含めたコストはもちろん、技術・ノウハウも必要ですから、規模によりますが、LLMを自分たちで一から作るということをビジネスとして組み込む組織は限られてくることになります。
大規模言語モデル・対話型生成AIの従来AIからの違い
LLMによるAIが世界に大きなインパクトを与えていることは皆さんご存じの通りでしょう。いろいろな理由があり得ますが、端的には、「開発プロジェクトなどを経ずとも、様々なタスクを一つのAIがこなせる」ということが大きいでしょう。これまでの教師あり学習技術などによるAIでは、AIにやらせたいタスクに対し、訓練データを整備してモデルを構築するというプロジェクトを経ることが必要でした。しかし、LLMに基づく対話型生成AIの場合は、日本語による指示入力(プロンプト)により様々なタスクを行わせることができます。この点「各自がうまく使うべし」という使い方での導入は非常に容易です。
なお、用途によってはもちろんこれでは不十分で、適した指示入力の方法を整備(プロンプトエンジニアリング)したり、独自の訓練データで追加学習(ファインチューニング)をしたり、知識データベースと連動したり(RAG: Retrieval Augmented Generationなど)が必要なことは当然あります。
LLMに基づく対話型生成AIにおいても、従来の教師あり学習技術などによるAIと同様の制限はあります。訓練データに強く影響を受け、例えば最新の事実について答えられなかったり、人種や性別に関して偏った回答をしてしまったりすることがありえます。また仕組み上、論理的な正しさやルールを確実に守るような保証は難しく、ハルシネーションと呼ばれる「もっともらしいが事実と異なる」回答もよく知られています。例えば2022年終わりの初期のChatGPTでは、「東京特許許可局」について聞くと、「特許庁内の組織で千代田区にある」といった、言葉のつながり上では非常に自然な嘘が出力されていました。
さて、本コラムの焦点である品質・トラストという観点では何か変わったでしょうか。これまで積み上げられてきたAIの品質やトラストの原則が変わったわけではありません。例えば、AIによる差別的な振る舞いは受け入れられない、といった原則は確立済みであり、対話型生成AIにも当然適用されます。一方で、対話型生成AIは入出力の形式が固定されないので、差別的な振る舞いといっても多種多様なものが考えられます。品質・トラストに関する要求定義や、テスト・評価という意味では難しさが段違いともいえます。
もう一つの点として、LLMについては、ほとんどの組織が、提供されたものを使うだけという立場になります。このため、内部設計や訓練データの評価を通して品質・トラストを論じることはできず、入力を与えたときの出力や外付けの仕組みだけで品質・トラストを論じることしかできません。その意味では、テスト・評価による品質・トラストの確認が相対的に重要になるといえます。
本コラムの次回以降においては、LLM・対話型生成AIの品質・トラストについてより踏み込んで動向を追っていきます。
これまでのコラム
第1回 機械学習技術によるAIの産業における活用
第2回 AIシステムにおける予測性能とデータ品質
第3回 AIシステムにおける広義の品質・トラスト (1)
第4回 AIシステムにおける広義の品質・トラスト (2)
第5回 AIの品質・安全性・トラストに関するガイドライン・標準
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
筆者紹介の詳細は、第1回をご参照ください。