

第4回 AIシステムにおける広義の品質・トラスト (2)
先月のコラムにおいては、AIシステムならではの品質やトラストの特性として、説明可能性と、追跡可能性・透明性について紹介しました。品質の高さあるいは、「信頼できる」というトラストの十分性を示すためには、それらを構成する異なる観点ごとに要求の定義や評価を行う必要があります。
本稿コラムでは、ソフトウェア工学の標準的な用語に倣い、そのような観点のことを特性と呼んでいます。今月も、AIシステムならではの品質やトラストの特性について紹介していきます。
公平性
AIシステムが実用化されていく中で大きな注目を浴びた一つの品質特性として、公平性があります。これはAIの判断が、人種や性別に対して不適切な偏りを持たないことを指します。雇用や犯罪捜査など個人に強い影響を与えるようなAIシステムでは、公平性を担保することが非常に重要と考えられています。もしかしたら、機械システムでは扱うことが少ないかもしれませんが、知っておくべき特性です。
公平性が問題となる、最もわかりやすい状況は、人種や性別などによってAIの予測性能が著しく異なるという状況です。
例えば、顔認証システムにおいて、訓練データの大半が白人男性であったため、他の人種や女性に対して精度が著しく低いことがありました。技術的にはこの例は、訓練データの不適切な偏りと、それに起因する予測性能の偏りを意味し、AIの開発者が差別を意図的に埋め込んだわけではありません。しかし、このように人種や性別によってAIの予測性能が変わってしまうようなことは、社会的には「差別的である」と言われ問題になります。
雇用や与信などの判断では、データの偏りだけでなく、訓練データに含まれる過去の差別的な判断が学習されてしまうことで、AIが差別的な振る舞いをとってしまうこともあります。ここで注意すべき点として、公平性を少なくとも二つの異なる観点からとらえる必要があります(図1)。雇用における性別の公平性を考えてみると、まず男女の採用率が同じになるべきという考え方があり得ます。これは「結果の公平性」を目指しているといえます。
一方、たまたま優秀な女性が多かった状況を考えてみます。この場合でも採用率を揃えることにすると、採用された男性よりも優秀だが採用されなかった女性が存在することが起きえます。すると「判断基準・手続きが不公平」と言えます。では逆に、年齢や経験、資格などに基づいた判断について男女で差がないようにすると、「判断基準・手続きが公平」となりますが、たまたま男女の採用率は揃わず「結果は不公平」となり得ます。偏りがある状況では、二種類の公平性は両立できないことがあるということです。
図1:AIのテスト結果に対する二種類の公平性の評価例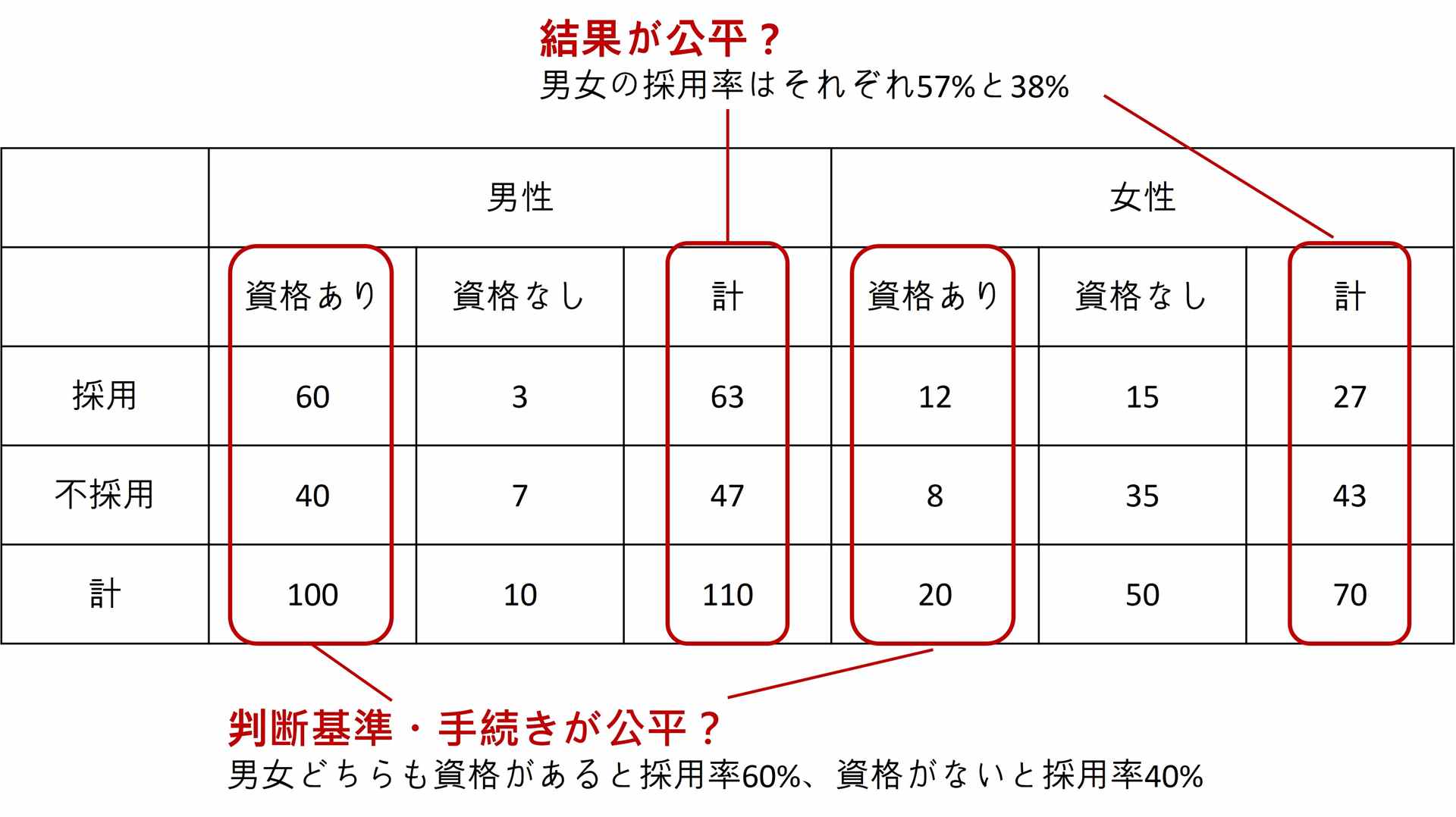
AIシステムの場合には、このような異なる種類の公平性についてその程度を測るような評価指標を用いてAIの評価や調整・改善をしていきます。そのための技術は2020年前後によく整理されており、MicrosoftのFairlearnなど多くのツールが提供されています。
当然ながら、二つの公平性についてどちらをどれだけ重視するかについては、AIの技術的な問題・開発者の問題というよりも、AIシステムの企画や発注、利用を行う組織、さらには社会での議論と意志決定が必要です。AIに関係なく社会においては、上記の二種類の公平性を「公平」と「平等」と呼び分けて議論がなされています。
頑健性
様々なノイズや摂動に対して強いという頑健性(ロバストネス)は、AIに限った特性ではありませんが、AI分野においては特に重要と考えられている特性の一つです。というのも、深層学習技術を用い複雑なモデルにおいて、入力にノイズを加えることで出力が大きく変わることがあり得ることがよく知られているためです。
そのことが広く知られるようになった例を図2に示します。画像に写る物体を分類するような深層学習モデルにおいて、左側の画像は正しく「パンダ」という出力を出すことができている状況です。ここで中央の画像のように「うまく計算された」ノイズを足すと、右側の画像になり人間から見るとほぼ何も変わっていません。しかし、右側の画像に対する深層学習モデルの出力は「テナガザル」に変わってしまいます。このような入力のことを敵対的サンプルと呼びます。人間にとって自然な判断基準をAIが用いているとは限らず、ノイズによって人間が思いもしない形で間違えるようなことが起きえます。
図2:敵対的サンプルの有名な例
この問題に対しては様々な対応策が提案されています。最も単純には、訓練データにおいて人工的に様々なノイズを加えることで、本質的な特徴・規則性を学習させることを狙います(敵対的訓練と呼びます)。
AIセキュリティ
AIシステムに関しては、固有の攻撃がいくつか知られており、それらを考慮したセキュリティ対策が必要となります。
敵対的サンプルについてすでに述べましたが、これを引き起こすため悪意を持って入力にノイズを加える場合、これは「敵対的攻撃」というセキュリティ上の問題となります。例えば、道路標識に色テープを貼ることで実際と異なる標識と誤認識させる、音声による指示に対し人間にはわからないノイズを加えることで購入指示と誤認識させる、うまく細工した眼鏡をかけることで誤認識させ顔認証を通過する、といった攻撃が実証されています。
狙った出力になるよう間違えさせることが簡単にできるわけではありませんが、訓練データや予測モデルの設計情報が漏れていたり、何百回も異なる入力ノイズで試行錯誤できると、攻撃が行いやすくなります。
他の攻撃として、公開されているAIサービスに対する攻撃を二種類紹介します。
一つは、訓練データの推測です。例えば、顔画像を入力とし、「女性」「眼鏡をかけている」「金髪」といった情報を出力するAIサービスがあったとします。このときに、訓練データに含まれている特定の人の画像が推測できてしまうと、プライバシーなどの問題につながります。
もう一つの攻撃は、「モデル盗難」と呼ぶのがわかりやすいでしょう。公開されているAIサービスにおいて、様々な入力を与えて実行すると、大量に入出力のペアが得られます。すると、そのAIサービスを真似するようなAIモデルの訓練を行うことができてしまいます。
いずれの攻撃も、公開されているAIサービスを大量に実行できれば実施できます。特にAIからの出力において、「女性」という答えだけでなく「女性0.78・男性0.22」といった確信度が含まれるとより攻撃が容易になります。これらの攻撃は、正常なAIサービスの利用の中でも実施できてしまいます。まずとれる対応としては、確信度を出力に含めないようにした上で、短い時間での大量の利用をブロックしたり、利用規約で出力を訓練に使うことを禁止したりすることになります。
本コラムでは、入力へのノイズ付加による敵対的攻撃、訓練データの推測、モデル盗難という三種類の攻撃を紹介しました。特筆すべきは、これらはどれも不正アクセスがなくても攻撃を実施できる点です。もちろん不正アクセスにより訓練データや予測モデルの情報が漏れてしまったり、細工されてしまったりすると、攻撃が容易になるので、従来のセキュリティ対策もした上で、固有のセキュリティ対策が必要になります。
まとめ
先月、今月の二回にかけて、機械学習型AIにおいて特に注目されている品質・トラストの特性について紹介しました。ここまでのコラムでは、大量データを用い機械学習技術による訓練を行うことで構築するAIシステムの品質・トラストについて論じてきました。
次回は、機械学習型AIシステムの品質・トラストに関するガイドラインや標準を紹介し、ここまでのまとめとします。
2022年後半のChatGPTが登場以降、大規模言語モデルと呼ばれる技術を用いたAIシステムの品質・トラストも盛んに議論されるようになっています。大規模言語モデルを用いたAIシステムについては本コラムの第6回以降にて紹介していきます。
これまでのコラム
第1回 機械学習技術によるAIの産業における活用
第2回 AIシステムにおける予測性能とデータ品質
第3回 AIシステムにおける広義の品質・トラスト (1)
筆者紹介 石川 冬樹(いしかわ ふゆき)
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
筆者紹介の詳細は、第1回をご参照ください。