

目次
- 開催概要
- 講演サマリー
- AI for Quality:テスト生成を例に
トピック1:品質のためのAI技術活用 - Quality for AI
トピック2:AIプロダクト・サービスの品質 - 対話型生成AIでさらに変わる世界
トピック3:対話型生成AIでさらに変わる世界 - 品質へのアプローチ
全体まとめ:AIと品質 - 講師紹介
1. 開催概要
開催趣旨
昨今、AI 、5G などの導入、流通・サービス等の機械化・ロボット化、産業のデジタルトランスフォーメーションなどの技術革新やカーボンニュートラルへの取り組みなどが進みつつあり、我が国の技術及び経済社会は大きな変革期を迎えています。
本研究会では、最新の機械システムの技術トレンドやデジタル活用の動向、注目すべき内外の動きなどについて共有し、意見交換を行うことを目的として、有識者の参画のもとにテーマごとに各分野の専門家を招いて講演いただいた後に議論を行います。
開催日時
開催日時:2024 年1 月 19 日(金)
場所:日本自動車会館 会議室
講演テーマ: AI 時代における製品・サービスの品質へのアプローチ
講師: 石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
2. 講演サマリー
最近はビジネスにおいてもニュースにおいてもAI(人工知能)の話が飛び交っています。とはいえ、ビジネスでの利用、特に機械や自動車の世界への適用においては、「品質」を定めて担保していくことが必要不可欠です。研究会では、ソフトウェアの品質とAIとの関係性について双方向から、つまり
・ 「品質のためのAI技術活用(AI for Quality)」
・ 「AIを用いたプロダクト・サービスの品質保証(Quality for AI)」
のそれぞれについて議論を行いました。最後に、今まさに大きな変化をもたらし続けている、ChatGPTをはじめとした対話型生成AIについても論じました。
3. AI for Quality:テスト生成を例に
トピック1:品質のためのAI技術活用
最初のトピックとして、品質のためのAI技術活用について考えてみます。AI技術と言っても多様なものがありますが、ここでは進化計算などのメタヒューリスティック最適化技術に注目します。データをたくさん集めて学ぶという機械学習ではなく、「繰り返し試してみて、よりよいものを選んでいく」技術と言えます。特に、自動運転など実世界で動作するスマートシステム・サイバーフィジカルシステムなどにおいては、シミュレーターを通常構築することになるので、「繰り返し試す」というアプローチは特別な準備なく適用できます。
従来ソフトウェアの品質においては、テストが非常に重要な役割を果たしてきました。テストの「良さ」を担保するために、少ない数のテストで「多様な」、あるいは「網羅的な」テストが行えることが重視されてきました。このために、「プログラムコード内の様々な要素を試したか?」というカバレッジ指標が用いられています。一方で、テストの数・規模をおさえつつ、カバレッジを高くするようにテスト一式(テストスイート)を揃えることは難しい問題です。このため、メタヒューリスティック最適化を用いて、与えた「テストの良さ」を最適化することで、よいテストスイートを探索する技術があります。この技術はSearch-Based Testingと呼ばれ、Facebookのモバイルアプリにおける適用例も有名です(図1)。
図1:Facebookにおけるテスト自動生成事例
最近の事例 : Sapienz (Facebook)
– Facebookにおけるモバイルアプリテスティング
– Continuous Integrationに乗せて、リリース候補に対し自動実行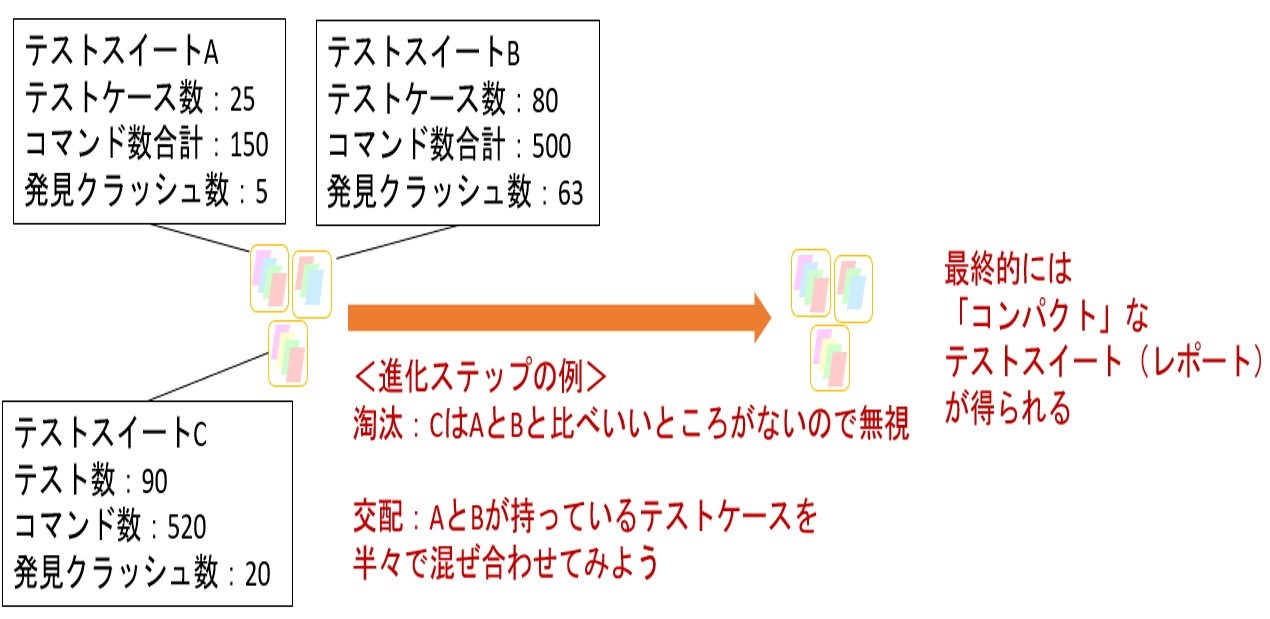
[ Mao et al., Sapienz:multi-objective automated testing for Android applications, 2016 ]
[ Alshahwan., et al., Deploying Search Based Software Engineering with Sapienz at Facebook, 2018 ]
新しいスマートシステム・サイバーフィジカルシステムの品質においても、テスト、特にシミュレーターを用いたものが非常に大きな役割を果たします。このようなシステムでは、「明確にルール化された指示されたことをやる」のではなく、自動運転をはじめとして、物理社会・人間・社会に深く踏み込んでそこで「適切なことをやる」ことが求められるようになっています。このためテストとして扱うべき品質の種別や考え方も広がっています(図2)。
図2:近年のスマートシステム・サイバーフィジカルシステム
最近広がっているシステム
AI, loT, サイバーフィジカル, スマートXX, …
– 人間・社会や物理世界に深く踏み込む
人事査定, 医療診断, …
自動運転, 店舗内ロボット, …
– 実装が「動作ルール書き出し」ではない
機械学習
最適化
⇒ 要求・想定環境の不確かさ + 実装された挙動の不確かさ
⇒ 何をもって 『よいテスト』 とするか?
筆者は、これまで自動運転、教育推薦システム、自動宅配ロボット、スマートフォンゲームなどのテストに関して産学連携を行ってきました。このようなシステムに対して、「適切なテスト」を表すようなスコアを議論し、メタヒューリスティック最適化を用いてそのようなテストを自動生成することを行っています。さらには、テストに限らず「見つけた問題に対する修正案」や「挙動の差を端的に表す具体例」などの生成も行ってきました。特に自動運転については多様なテスト目的を踏まえた自動生成や、その結果を受けての分析や修正、つまりデバッグについても取り組んできました(図3)。
(参考ページ)
https://www.nii.ac.jp/news/release/2020/0323.html
https://www.nii.ac.jp/news/release/2021/0412.html
https://www.nii.ac.jp/news/release/2021/1115.html
図3:自動運転における技術事例
事例 (1) 自動運転における経路計画
-オマケ:開発した技術の一覧
| a. テスティング | (a-1) 問題検出指向 | 「避けられたはずの衝突」のみ検出 |
| 多数の要求に対する違反を適応的に探索 | ||
| (a-2) 網羅性指向 | 事故に至らない状況での急ブレーキや急ハンドル それらの複合発生を探索 | |
| 「少し設計を変えると大きな差がでる」ように 反応性が高いテストを探索 | ||
| b. デバック | (b-1) 要因分析 | 検出した衝突等に対し、どのパラメーターが影響したかを分析 |
| (b-2) テスト単純化 | 検出した衝突等が起きるがもっと簡単なテストを探索 | |
| (b-3) 自動修正 | 検出した複数の問題点に対処する修正案を探索 |
4. Quality for AI
トピック2:AIプロダクト・サービスの品質
より広く産業界・社会の注目を集めている方向性として、AIを用いたプロダクトやサービスの品質という観点があります。より広い観点で、倫理やトラストという言葉で論じられることもあります。
ソフトウェア開発という観点では、機械学習技術を使って構築されたAIが持つ異なる特性に着目する必要があります(図4)。
これまで仕様書としてソフトウェアの振る舞いをルールのように与えていたのに対し、入出力の例を大量に定める訓練データの中に「期待すること」が表現されていることが必要になります。また、訓練データから導かれた振る舞いをシステムに乗せることになり、その振る舞いが不確かだという課題もあります。評価においても、振る舞いの規則性が見えないので、「試してみた入力では大丈夫だった」ということしか理論上は言えません。
図4:従来ソフトウェアと機械学習
従来ソフトウェアと機械学習:成果物の視点
従来ソフトウェア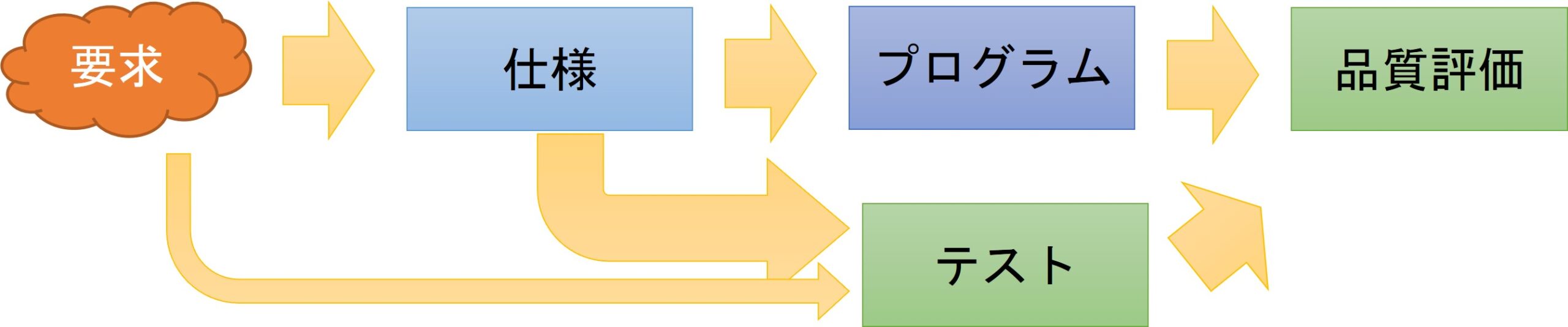
※工程はかなり簡素化
※実際のシステムでは両方を統合
機械学習型AI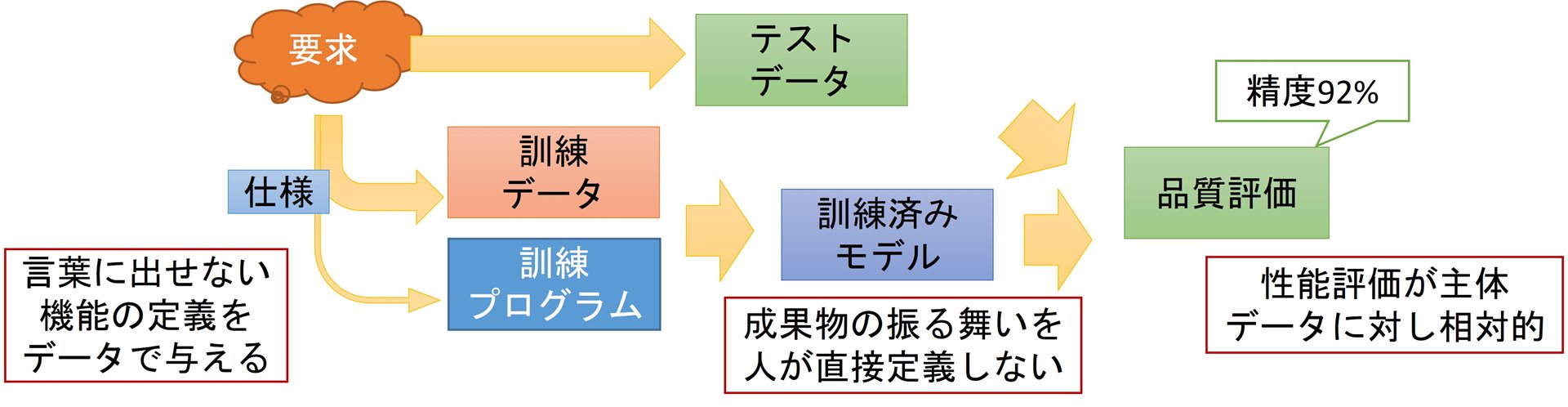
機械学習型AIの品質については、国内ではいち早くガイドラインの策定が行われてきました。AIQMという、産業技術総合研究所主導で、標準のように規範的に、言葉を明確に一般的な指針を示したものがその一つです。また、QA4AIという、ボランティアとして品質保証やテストの実務者を中心に、具体的なアクションを定めたガイドラインもあります。
(参考ページ)
https://www.cpsec.aist.go.jp/achievements/aiqm/
https://www.qa4ai.jp/
いずれのガイドラインにおいても、訓練および評価に用いるデータの品質について述べられています。要求あるいは想定する運用環境を踏まえて十分なデータを揃える必要があります。以下では領収証読み取りという比較的簡単な領域について示していますが、それでも本気で「多様な種類のデータ」が十分にあることを確認しようと思うと、非常に大変だということがわかります(図5)。
このような理想を踏まえつつ、重要性あるいは失敗のリスクを踏まえて、現実的な品質のあり方を探っていく必要があります。
図5:データの十分性
データの「場合分け」の例
– 文字認識において対応すべき状況(QA4AIガイドライン)
[1] プレ印字の有無・色
[2] 株式会社や年号の異なる表記
[3] 印鑑かぶり
[4] ボックス区切り・網掛け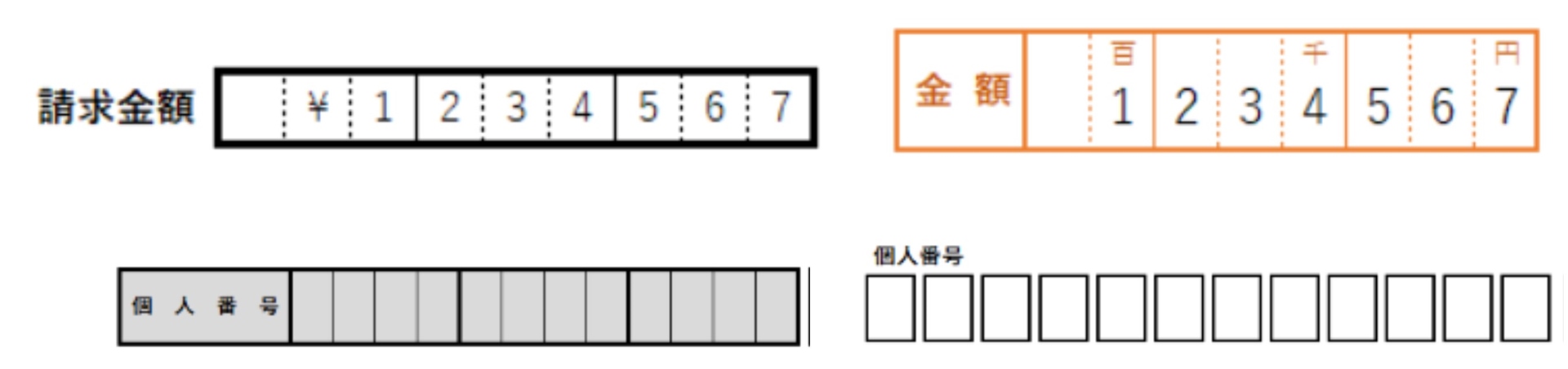
(出典) http://www.qa4ai.jp/
なお、筆者は研究者の立場として、機械学習型AIを要件に合わせてうまく調整する、そして更新し続けるための技術に取り組んでいます。深層学習と呼ばれる技術を用いた場合、データに基づく訓練で500万以上のパラメーターを設定することになります。このため、特定の外し方を避けたいといった調整が困難であったり、以前のバージョンとの互換性を保つのが難しくなります。筆者らの取り組み(Engineerable AIプロジェクト)では、プログラムのデバッグのように、問題があるパラメーター群を推定することで、保守的に絞った更新を行う技術に取り組んでいます(図6)。
(参考ページ)
https://engineerable.ai/
https://www.nii.ac.jp/news/release/2023/0317.html
図6: Engineerable AI プロジェクトでの取り組み
“Engineerable AI” プロジェクトでの研究:技術側面
<従来>

<提案:深層学習デバッグ技術>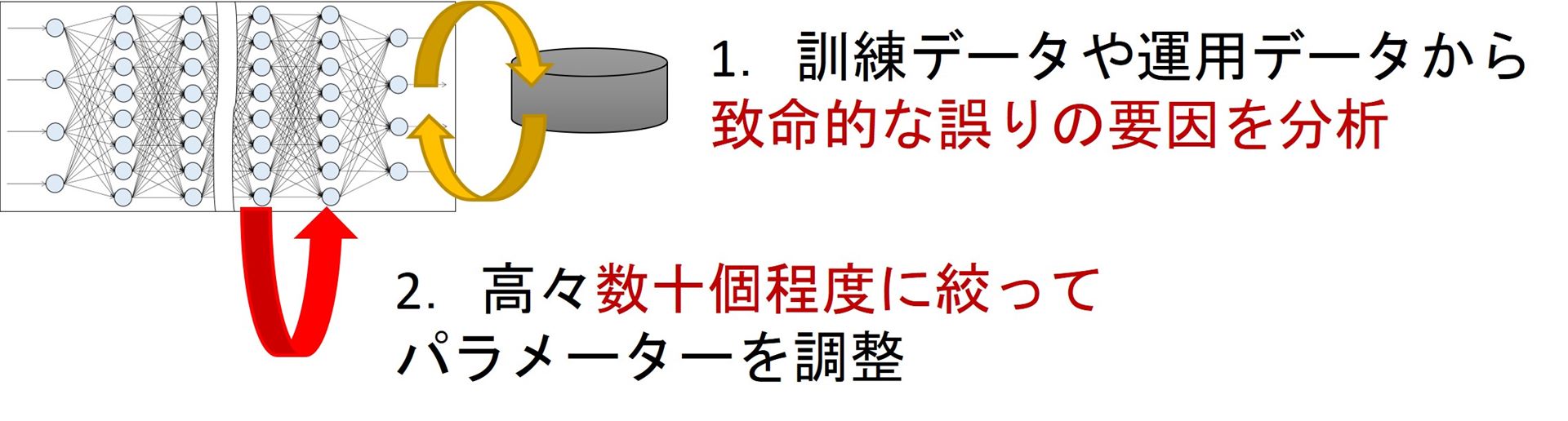
![]()
調整対象を絞るから
致命的な誤りに対して高い効果の修正が可能
成功していた部分に影響を与えない修正を追求可能
複数の修正案を効率よく提示可能
従来プログラムの欠陥に対する技術を発展!
5. 対話型生成AIでさらに変わる世界
トピック3:対話型生成AIでさらに変わる世界
以上のような議論がAIに関してなされていましたが、2022年秋のChatGPT公開以降、また別の種類のAIとして大規模言語モデル(LLM)に基づく、対話型生成AIが非常に注目されるようになりました。ものすごく大ざっぱには、「続きを予測する」ような学習を大量にしているのですが、その結果、翻訳、要約、言い換え、質問応答、プログラム作成・修正、プログラム説明など多様なタスクを行えるAIとなります。これは従来、タスクごとに入出力の例を多数準備して訓練し開発していたAIとは異なり、非常に汎用性が高いものとなります。さらに、自然言語での入出力を扱えるため、エンドユーザーが直接使え、しかも立場などの指示により出力を自身で制御、調整することができます。筆者は、これらの点が大きなパラダイムシフトであると考えています。
以下の例では、ソフトウェアエンジニアが行うような、「大まかな要件記述から、時系列でシステム機能を洗い出す」という例を示しています。利用者登録、検索、予約がこの順に並ぶという時系列や、ワクチン接種予約システムには接種証明発行機能も必要だろう、といった点は、指示に全く含めていませんが、学習した「常識」から勝手に補われています(図7)。
図7:対話型生成AIの一つの実行例
一つの実行例:ユースケース構造化・補完・分析
一方、対話型生成AIについては、ハルシネーションと呼ばれる「自然だが事実に基づかない、もっともらしい嘘」の問題が注目されています(図8)。
他にも、犯罪行為をおしえてしまうといった悪用、攻撃的な発言、「消防士といえば男性」といった差別的な偏りの存在など多くの懸念があります。
図8:もっともらしい嘘の一例:東京特許許可局
「嘘をつく」例とその変遷
【1】ChatGPT Feb 13 ver. (GPT-3.5)
それらしい嘘をつく例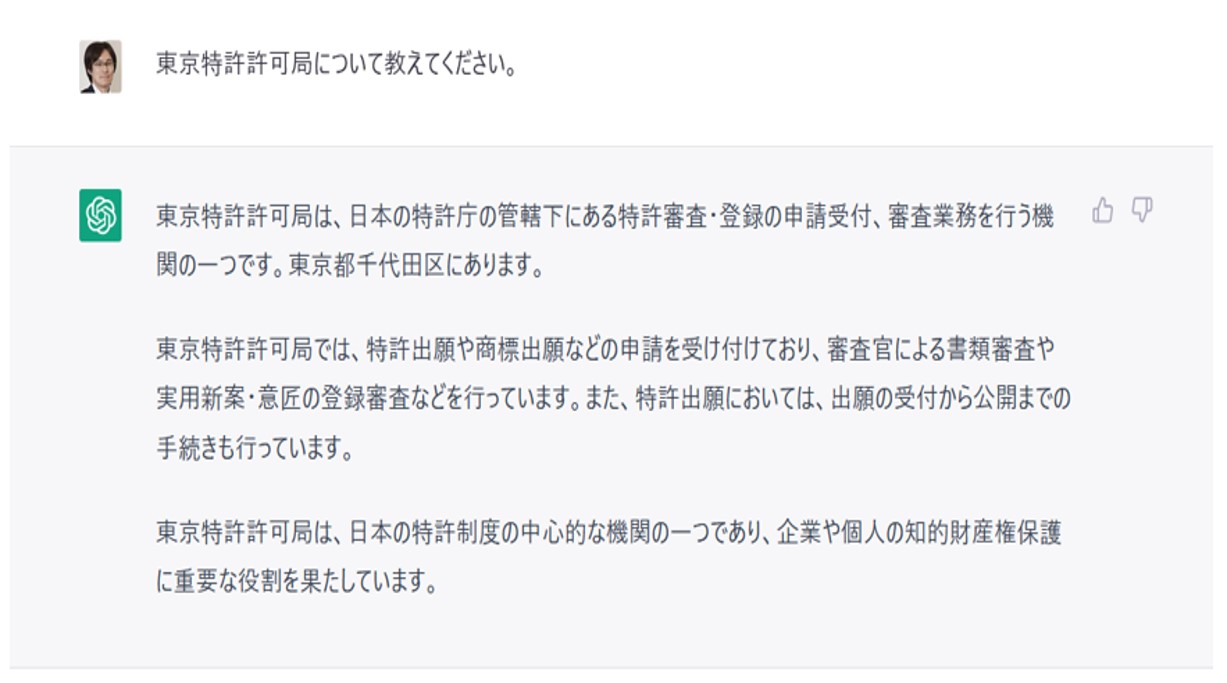
駅と路線の対応や距離関係もおかしい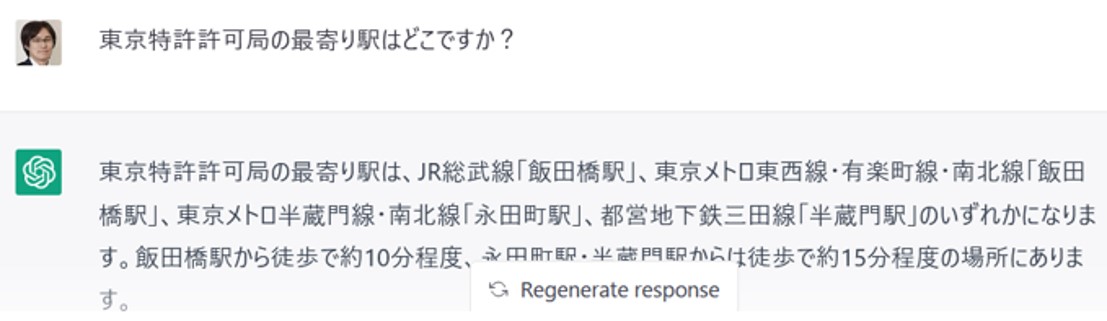
【2】 ChatGPT Jul 20 ver. (GPT-3.5)
お断りの言葉が入るように
【3】 ChatGPT Jul 20 ver. (GPT-4)
最新版では学べている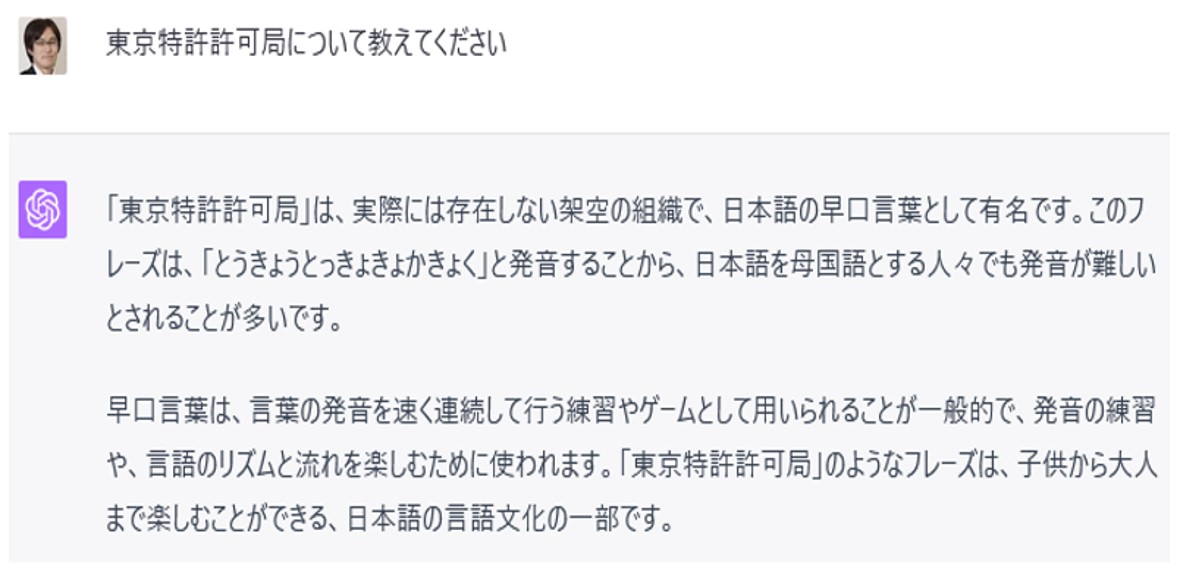
このような対話型生成AIにより、ソフトウェア開発やその品質がどう変わるか、あるいは、このような対話型生成AIの開発や品質をどう扱っていくか、という二つの方向性が今まさに議論されています。研究会前々日には、QA4AIガイドラインにおいて、対話型生成AIの品質を扱うガイドラインがまさにリリースされたところでした。
(参考ページ)
https://www.qa4ai.jp/
https://speakerdeck.com/ishikawafyu/quality-assurance-for-generative-ai-at-qa4ai
以上のように、AIはプロダクト・サービスを送り出す助けとしても、プロダクト・サービスの一種としても、新しい可能性・課題を投げかけ世界を大きく変えてきました。特に対話型生成AIについては非常に変化が速く、その変化への追随の戦略や体制も大きな課題となっています。このように世界が変わる瞬間に我々は立ち会っており、これからも楽しみながら、挑戦を続けていければと思います。
6. 品質へのアプローチ
全体まとめ:AIと品質
高い不完全さ・不確実性が原則に
– 要求・環境・傾向の膨大さ + 実装した挙動の理解困難性
– 実世界や社会に大きく踏み込むことが増加
– 不確かなものに対する試行錯誤の反復継続
– めまぐるしく変わる世界
ステークホルダーの議論を通し不完全・不確かなものを受け入れ
自動化された探索・テスト・測定・監視による継続的進化を
&
新しい技術・時代の変化を楽しみましょう!
7. 講師紹介
石川 冬樹 国立情報学研究所 アーキテクチャ科学研究系 准教授
【研究分野】
ソフトウェア工学、自律・スマートシステム、機械学習工学、ソフトウェアテスティング、形式手法、サイバーフィジカルシステム、サービス指向コンピューティング
【略歴】
国立情報学研究所 アーキテクチャ科学研究系准教授、および先端ソフトウェア工学・国際研究センター副センター長。 ソフトウェア工学および自律・スマートシステムの研究に従事。 近年は、自動運転やAI システムの品質や安全性に関する技術について、産業界と密に連携して幅広い活動を行っている。 AI 品質保証コンソーシアム副運営委員長。博士(情報理工学)。