

令和5年度 第1回 生成AIの機械システム設計開発への活用フォーラム 講演サマリー
講師: 今井 翔太 様 東京大学大学院 工学系研究科 技術経営戦略学専攻
©2023 Shota Imai | The University of Tokyo
(本コンテンツの著作権は、今井 翔太様に帰属いたします。)
1. アジェンダ
- 生成AI/ChatGPTの基礎知識
– ChatGPTとは
– 言語モデルの原理
– ChatGPTの学習 - ChatGPTの活用
– ChatGPTの動作原理
– プロンプトエンジニアリング
– ユースケース
– 使用上の留意点
2. 生成AI(Generative AI)
█ 生成AIは,言語生成AI(ChatGPT, PaLMなどの大規模言語モデル)や画像生成AI(Stable diffusionやMidjourneyなどの拡散モデル)のように,「人間が行うような新たなアイデアやコンテンツを作り出す能力を持つ人工知能の一種 」である
その他,音声,分子構造など,生成できる対象は幅広い
3. GPT,言語モデルとは?
GPTは「Generative Pre-trained Transformer」の略で,OpenAIが開発している
Transformerというニューラルネットワークをベースにした大規模な事前学習済み言語モデルを指す
█ 言語モデル(Language Model)
– 単語や文章が生成される確率をモデル化したもの
– 例えば,以下のような文の穴埋め問題で,「このりんごはとても」までを入力して,次の( )にはいる単語の確率を出力し,最も高い確率の単語を割り当てる
文:このりんごはとても( )
(1) おいしい 0.8
(2) 寂しい 0.1
(3) です 0.05
(4) ペン 0.05
→「おいしい」を出力
– GPTは,このような文章の「穴埋め問題」を大量に事前学習させたニューラルネットワーク
4. プロンプト(Prompt)
█ 言語モデルの出力を得る(促す, Prompt)ために,言語モデルに入力する文字列,指示文を指す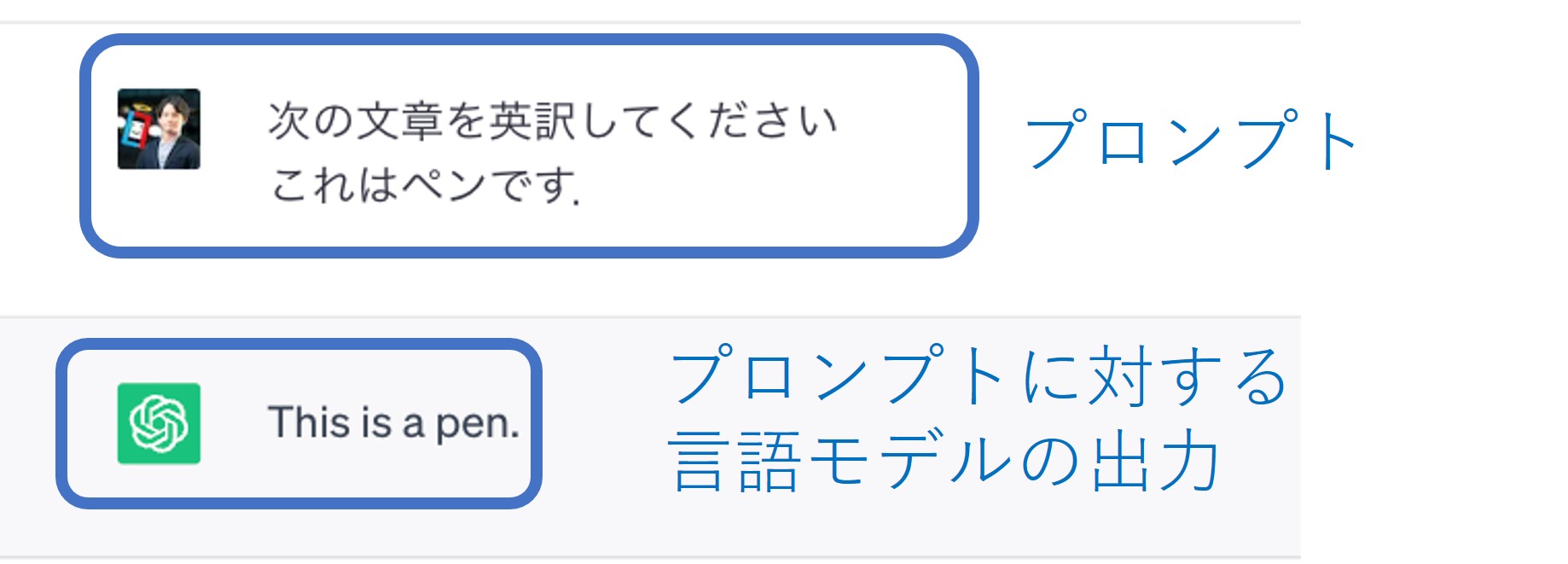
█ 言語モデルの知識から所望の出力(プログラムコード,提案,翻訳文,質問回答)を得るには,適切なプロンプトを入力する必要がある
█ プロンプトを工夫してAIに所望の出力をさせる技法の試みは
プロンプトエンジニアリングとも呼ばれる
5. 言語モデル/GPTの動作
█ 現在のGPT/言語モデルの出力は自己回帰的であり,ユーザーからのプロンプトとGPT自身の出力を入力として,逐次的に文章を生成する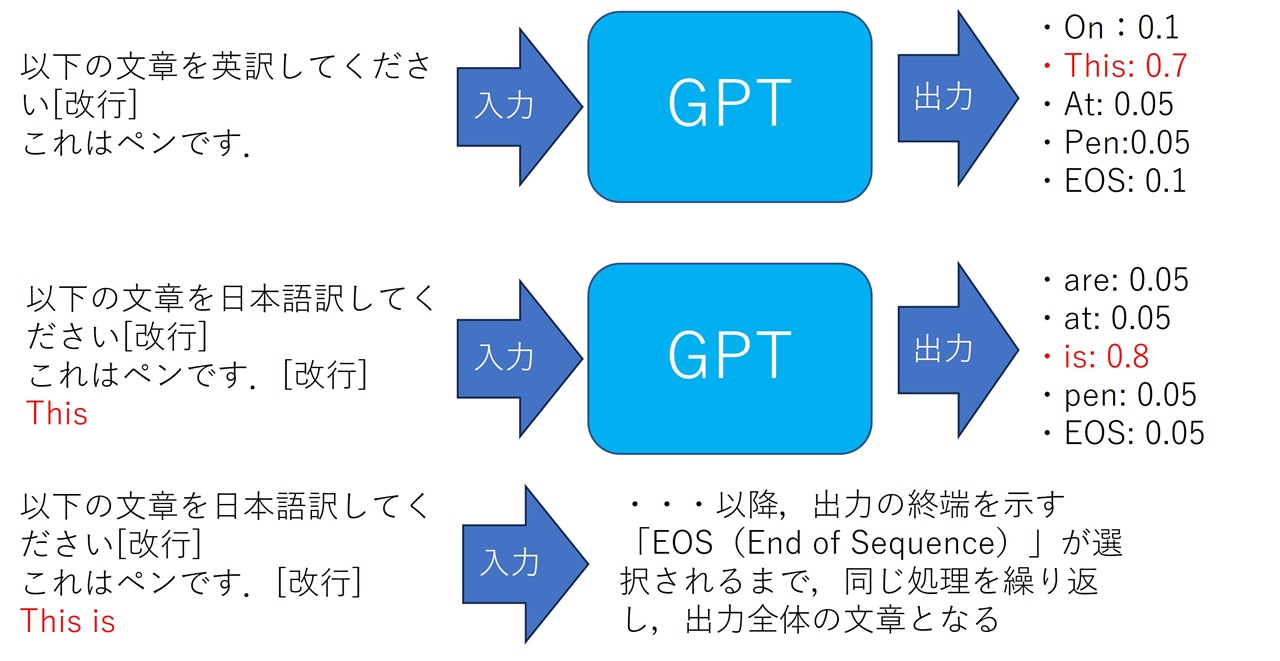
6. ChatGPTの動作原理
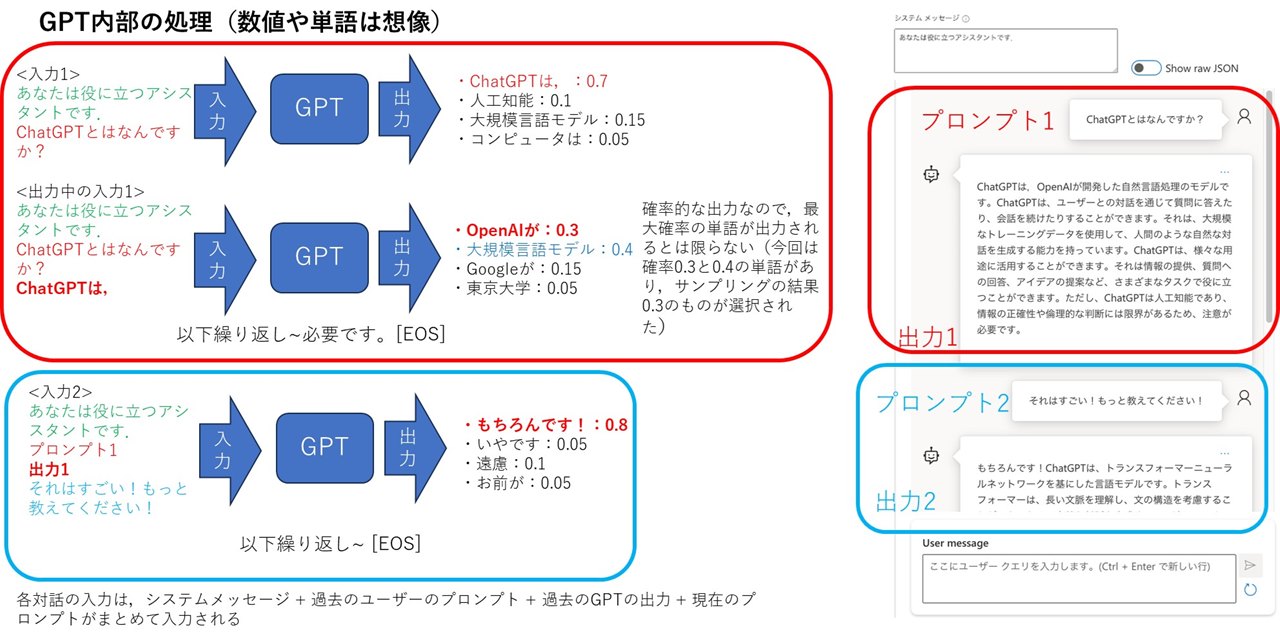
7. ChatGPTに関わる設定・パラメータ
█ システムメッセージ
– ChatGPTに対する各プロンプトの先頭に必ず記述されるプロンプト
– 与えたい役割や,出力形式を指定する
█ 温度(Temperature)
– 出力の候補単語の確率分布をばらけさせることで,文章の多様性を向上させる
█ 上位p(Top-p),上位k(Top-k)
– 出力の候補単語の中で,どの範囲の単語を出力のサンプリングの対象にするか決定
█ Maximum length
– 出力文章の最大長を調整
█ Frequency penalty,presence penalty
– 同じ単語を出やすく/出にくくする
8. プロンプトエンジニアリング
█ ChatGPTのようなLLMに与えるプロンプトについて工夫,研究,最適化を行う新しい分野
█ LLMは膨大な知識を内包し,それを記述する能力も優れているが,人間が与えるプロンプトによって出力に大きな差が出る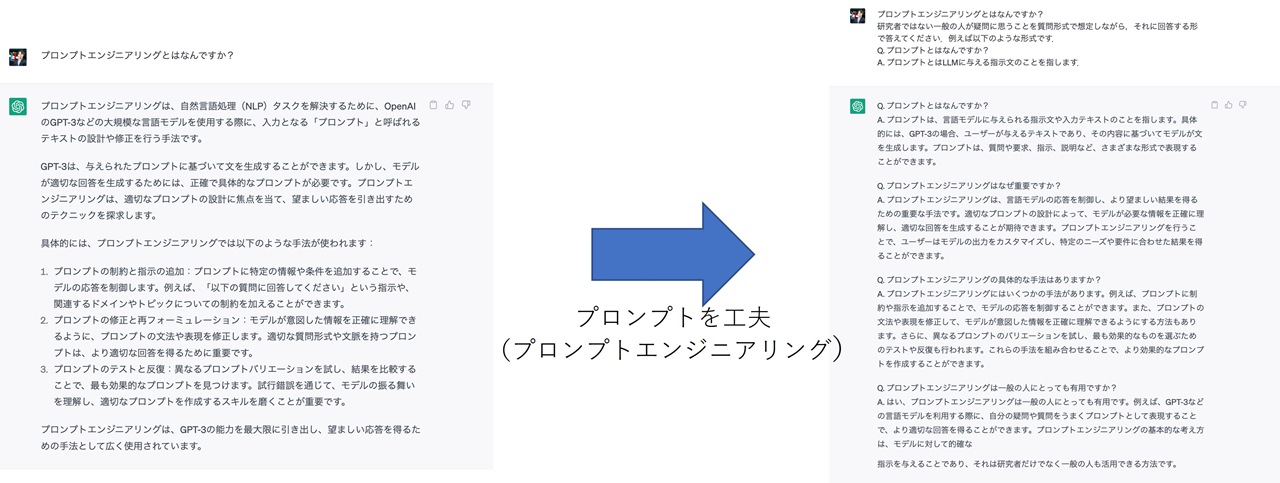
9. プロンプトエンジニアリングの具体的手法
█ Zero-shotプロンプティング
– 回答例を与える等の工夫をせず,プロンプトを入力する手法
– 従来の大規模言語モデルではあまり機能しなかったが,性能向上により十分に機能
█ Few-shotプロンプティング
– 少数の回答例を与え,解答を出力させる手法
– 大規模言語モデルから所望の出力を得やすくなる,最も一般的な手法
█ Chain of Thought(思考の連鎖)プロンプティング
– プロンプトの最後に「Let‘s think step by step」などという,思考の過程を記述する指示を追加することで,出力の精度を上げる手法
– 大規模言語モデルは論理的な問題の回答が苦手だったが,この手法により劇的に性能改善
10. ChatGPT等のLLMのユースケース
█ 知識整理,要約
– プロンプトとして既存の文章を与え,その文書に対する質問を行う
– 文書に関連する知識の出力,要約
█ 読解と発見
– 長大な文書を高速に処理可能
– 文章中の誤り,不自然な表現,コードにおけるエラーの発見
– コードの意図の処理内容・意図の自然言語による説明
█ 翻訳,変換
– ある言語から別の言語への翻訳,プログラミング言語間の変換
– 非構造データから構造データへの変換(文章からjsonなど)など
11. 使用上の留意点
█ 個人情報,機密情報の入力
– OpenAIはユーザーの入力をChatGPTの学習に使う
– 個人・機密情報を入力すると,それが学習に使用され,将来的に他の人がChatGPTを使用した時に漏洩する可能性
█ ハルシネーション
– 現在のChatGPTなどの大規模言語モデルは,ある知識・事実に関して誤った出力をしてしまうハルシネーションが問題となっている
– 現在の研究段階ではこれを回避する手段はなく,ChatGPTの出力情報を使用する場合は注意が必要
█ トークン制限
– 大規模言語モデルは,ベース技術のTransformerの仕様上,入力できる文字数(トークン数)に制限がある
– 現時点では,社内文書,コードベースをまとめて処理することは困難
█ モデルの性能変化
– OpenAIはChatGPTのモデルを更新しているが,最新版で一部の性能が悪化していることが報告されており,必ずしも最新のモデルを使うのが良いとは限らない